 みなさん、初めまして。ソフトウェア設計課の楊です。
みなさん、初めまして。ソフトウェア設計課の楊です。
私がプログラム開発する中で一番難しいと感じたのはアルゴリズムの実装です。
アルゴリズムの中には面白いものがたくさんあり、最近機械学習に関連する強化学習の一つであるQ-Learningに触れる機会があり、それを実証するプログラム(Cheese Puzzle Simulator)を作成してみました。
Q-Learningは、強化学習のアルゴリズムの一つで、自動運転からフィンテックまで様々な分野で活用されています。
ここでQ-Learningのアルゴリズムを簡単に紹介したいと思います。
<課題>
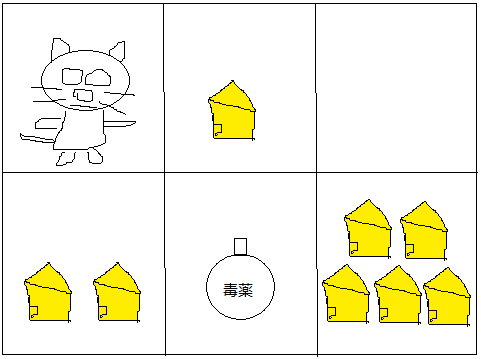
図に示すように迷宮にネズミとチーズと毒薬があります。ネズミはどういうふうに行けば一番高いポイントでチーズの山に辿り着きますか?
ポイントは、チーズ*1個=1, チーズ*2個=2, チーズの山=10, 毒薬=-30, 何もない=-3とします。
<解説>
簡単に説明するために小さめの地図を採用しましたが、迷宮が大きくなると通常の方法では解決しにくいと思います。そこでQ-Learningのようなアルゴリズムが作られました。
Q-Learning はルールの下で、状態ごとの全ての実行可能なアクション予測値を学習するものです。ルールをR-Tableで、状態とアクションの組の予測値をQ-Tableで作ります。Q-Table は学習する必要があります。
① まずQ-Tableを初期化します。(下表参照)
| ← | → | ↑ | ↓ | |
| Start | 0 | 0 | 0 | o |
| Cheese*1 | 0 | 0 | 0 | 0 |
| Nothing | 0 | 0 | 0 | 0 |
| Cheese*2 | 0 | 0 | 0 | 0 |
| Poison | 0 | 0 | 0 | 0 |
| Cheese Mountain | 0 | 0 | 0 | 0 |
② 次に R-Tableを設定します。(下表参照)
| ← | → | ↑ | ↓ | |
| Start | 0 | 1 | 0 | 2 |
| Cheese*1 | -3 | -3 | 0 | -30 |
| Nothing | 1 | 0 | 0 | 10 |
| Cheese*2 | 0 | -30 | -3 | 0 |
| Poison | 2 | 10 | 1 | -30 |
| Cheese Mountain | -30 | 10 | -3 | 10 |
③ 最後は次の数式でQ-Tableを更新(学習)します。
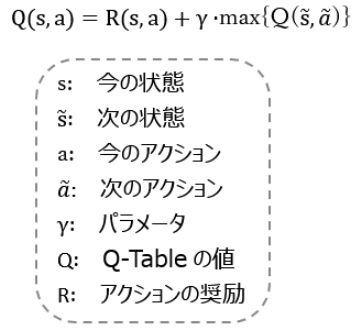
この問題は演算を重ねるとQ-Tableの値は収束していきます。
次の画像は上の設定(パラメータγ:0.6)を使って模擬したものです。(ネズミは常に高い数字のアクションを取ります)
大体200回ぐらい演算すると結果が出て、Startの行から見ると、ネズミは目先の大きめのチーズを選ばずに直接チーズの山へ向かっていました。

以上、Q-Learningのアルゴリズムについてご紹介しました。
Q-LearningにDeep-Learningを応用したものとしてDQN(Deep Q-Network)というものがあり、限りなく大きいQ-Tableをニューラルネットワークによって習得して知能エージェントを作成することができます。AI Playerはその応用例の一つです。
私もDQN を使ってAI Gameを作成したことがあります。DQNの中で使ったニューラルネットワーク自体は先端のモデルでもなく、普通のCNN(Convolutional Neural Network:畳み込みニューラルネットワーク)です。
大事なのは複数の分野にまたがってDeep-Learningを応用する複合的な発想だと思います。
こんな中でAIoTという概念が生まれて、これから私たちの生活スタイルを大きく変えるのではないかと思います。
【関連リンク】
- ソフトウエア設計受託サービス
- 電気・ソフト設計受託サービス
- M5stackで簡易Wi-Fiチェッカーを作ってみました
- 無線モジュール搭載IoT機器の開発には幅広い知見と技術が必要です
- IoT化のお手伝い-ワンストップでアイデアを形にします
- IoTのプロフェッショナルを顧客社内に育成する「テクノシェルパ」登場
- WTIブログ(IoT関連)
WTIメールマガジンの配信(無料)
WTIエンジニアが携わる技術内容や日々の業務に関わる情報などを毎週お届けしているブログ記事は、メールマガジンでも購読できます。ブログのサンプル記事はこちら
WTIメールマガジンの登録・メールアドレス変更・配信停止はこちら

WTIの技術、設備、設計/開発会社の使い方、採用関連など、幅広い内容を動画で解説しています。